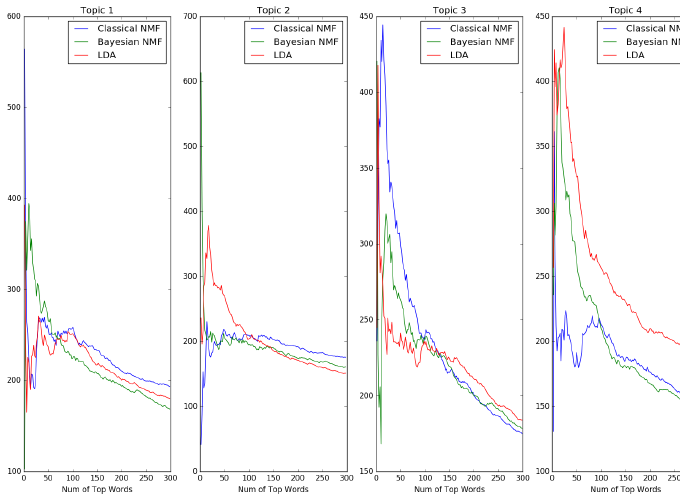
We define a topic modeling to partition documents into associated topics with nonnegative matrix factorization (NMF). We apply classical approach and also Bayesian inference with Kullback-Leibler error measure for approximating the decompositions of the matrix. As a baseline, we use topic model with LDA to compare it to our model. We evaluate our proposed method by defining domain specific metrics such as topic-uniqueness and overall topic-uniqueness. With our topic modeling approach, we provide efficient processing of large collections while preserving the essential statistical relationships. We show that our nonnegative matrix factorization reveals hidden topics and can be used for clustering and dimension reduction. Both of our nonnegative matrix factorization models can be used depending on the domain to obtain best overall topic-uniqueness.
For details, please click for the report
For the details of Bayesian NMF, please click for the poster
)