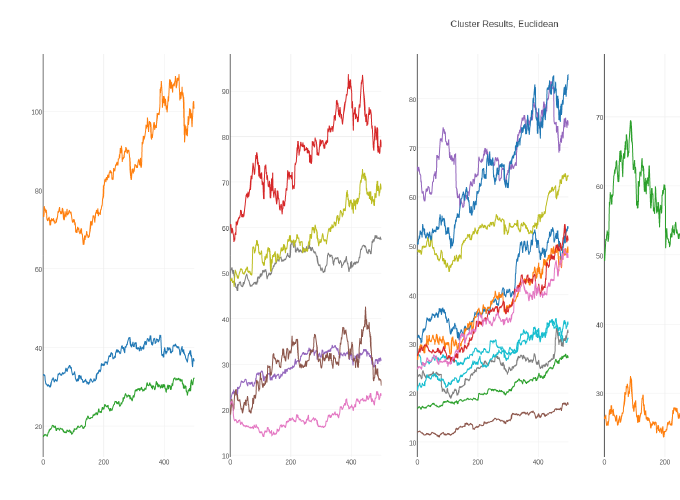
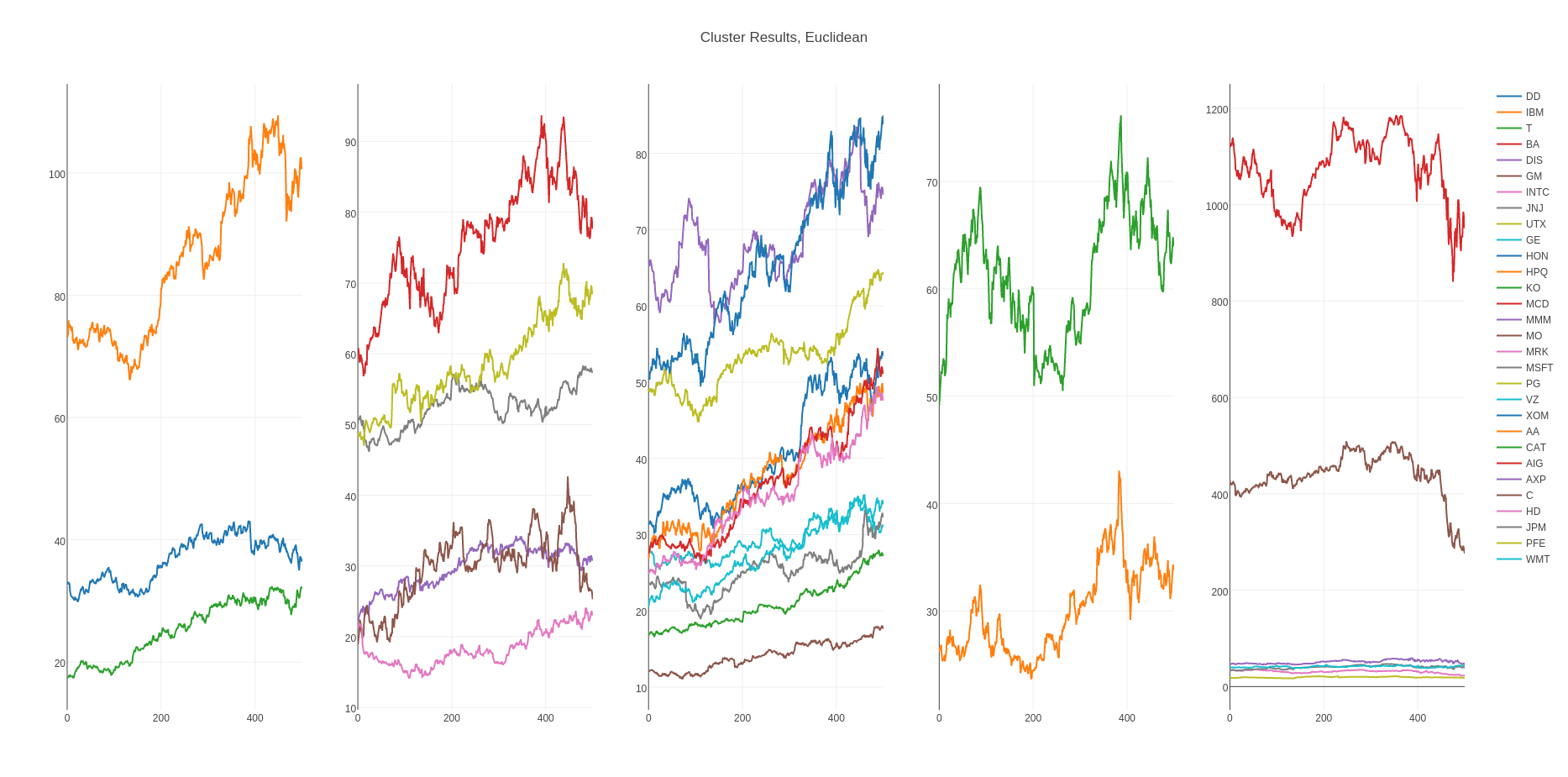
In order to reveal similarities and differences in time-series, finding underlying hidden trends, can be thought as all trends which are explaining a whole timeseries set, is very important. In the project, with the help of decompose a mixture data via Non-negative matrix factorization (NMF), time series into its constitute parts, the underlying trends extraction is tried to achieve. After NMF reveals underlying trends (bases), resulting encodings become prepared for clustering with k-Means algorithm. Finally, time series would be clustered together into performance-based groupings.
For the time series, the daily closing prices of the Dow Jones Industrial Average stock components are used as data-set. It contains 501 daily closing prices of 2 years (2006, 2007) of 30 stocks which is accessable with QuantSoftware ToolKit package in Pyhton.
For details, please click for the report
For NMF implementation, please click for the GitHub repository
For PCA implementation, please click for the GitHub repository
)