Was ist Informatik? – Eine andere Sichtweise
Die gängigen Erklärungen zu “Was ist Informatik?” – etwa von der Gesellschaft für Infomatik, der TU Dresden, oder auf Wikipedia – machen es einem schwer, sic...
|
As an introduction to the idea of Bayesian search please
(or download its source code) In this game you are to find maxima of a smooth 1D function. Humans certainly have some kind of prior about where optima might be depending on assumptions about the smoothness. And we update this prior to posteriors when we observe new data from the function. |
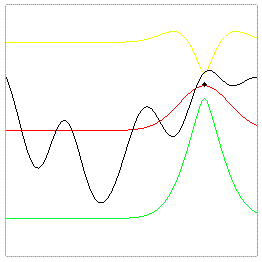
|
The same approach can be realized algorithmically. The `opponent' algorithm in the game starts off with a flat Gaussian Process prior over the function (which is actually the correct prior from which the objective function was really sampled). When new data from the function is observed the prior is updated to become a posterior (eventually this is what I mean by Bayesian search). Now, this posterior precisely describes the expected mean of the unobserved function and any point but also the uncertainty (variance) about this expectation. In some sense (the Bayesian sense) this is optimal: the posterior really reflects what one can possible have learned about the function given the few observations. This posterior is a very suitable basis for heuristics to choose a new search point: for every point we can, e.g., check if the expected mean is larger than our best-so-far. Or, also accounting for the uncertainty, we can explicitly compute the probability that the function value at some new point is larger than the best-so-far, or what the expected improvement is. (The improvement is defined as zero if the new function value is less than the best-so-far, and the difference if it is larger.) Maximizing such quantities leads to very efficient search heuristics.
This approach is also closely related to the POMDP framework. (Partially Observable Markov Decision Process.) Here an agent needs to take actions in a world of which he can't fully observe the state. What he can do though is maintain a belief about what the state of the world might be (in form of a distribution over the states). Again, given some new observations this belief can be updated in a Bayes-optimal way and in this sense the belief is all the knowledge the agent could possibly have about the current state of the world. POMDP theory shows that optimal behaviors can be based on the belief (the optimal policy is a mapping from belief to action). I guess the analogy to search is clear: The unknown state of the world corresponds to the unknown objective function; the actions correspond to picking a new search point.
This analogy at the same time also tells us what we'd need for a hypothetical optimal search strategy: the long-term reasoning about actions, i.e., choosing the current action not only for the immediate benefit but also for future benefits. In the POMDP case it is very intuitive that the optimal action often is one that gathers information, reduces the uncertainty in the belief and pays off later. The same is actually true in the search case. An optimal searcher would have to reason whether search points should be positions to maximize the immediate expected improvement or rather to learn as much as possible about the function to ensure later improvement. Formalizing all this is not the problem! Realizing this is notoriously difficult. The computational cost of such lookahead search point planning explodes already for a 2-step lookahead. What seems sensible though are heuristic approaches that lead to a trade-off between learning about the function and seeking for high values -- in the end this is often also the more practical approach to Reinforcement Learning problems rather than aiming for an optimal trade-off via the POMDP formalism. If you like, try yourself to do some lookahead planning of search points in the Bayesian Search Game! :-)
Formulated in this way, this nicely relates to the idea of Bayesian search: If we start with an unstructured prior over the space of functions, then the Bayesian update of this prior given an observation is still completely unstructured on the yet unobserved points. That's why we can't predict anything about yet unobserved points (no generalization) and any algorithm is as uninformed as random search when it comes to the yet unobserved sites. Further, NFL theorems can inversely be interpreted that one always should have a specific class of functions in mind -- or a specific prior over functions -- when designing a search algorithm, because a generically good search algorithm doesn't exist. But then, if you have to start with a prior over functions anyway, then the most natural thing to do is to update this prior based on observations and maintain a proper belief over the objective function. If this is computationally feasible it seems like a waste not to do this. The belief, including the mean estimates and its uncertainties, should always be a valuable resource when it comes to deciding on new search points.
Since I like to think about things and NFL and search in terms of distributions I settled for myself on a slightly different formulation of NFL with a rather simple proof. This is really just a matter of taste. In this formulation the emphasis is not about set of functions or closure under permutation. It is solely on distributions over functions. Please note that the notion `a set of functions is closed under permutation' is very closely related to `in a distribution over functions the function values at any two points are mutually independent'. That is important to realize and I think mutual independence is much more intuitive than closure under permutation. [I only have a first draft yet of this alternative formulation; proving the necessity of the condition is not that easy... contact me if you want to see the draft.]
Die gängigen Erklärungen zu “Was ist Informatik?” – etwa von der Gesellschaft für Infomatik, der TU Dresden, oder auf Wikipedia – machen es einem schwer, sic...